Die interessanten Anwendungsfelder liegen auf der Hand. Zum einen ist fundiertes Wissen über die Verhaltensmuster und Profile der am meisten und am wenigsten profitablen Kunden der Schlüssel zur Entwicklung erfolgreicher Marketingprogramme. Des weiteren ist ein besseres Verständnis der Kundensegmente entscheidend für die Konzeption von Kundenbindungs- und Kundenentwicklungsprogrammen. Und schließlich sind effektive Werbekampagnen überhaupt erst durch eine wissensbasierte Ermittlung der Zielgruppe möglich.
Data-Mining-Methoden
Um Wissen aus Daten zu gewinnen, bedient man sich moderner Analysetechniken, die unter dem Begriff Data Mining zusammengefasst sind. Mit Hilfe dieser Techniken lassen sich in den Daten interessante Muster automatisch erkennen und anhand von Modellen beschreiben.
Im Gegensatz zu traditionellen Analyseverfahren, bei denen der Anwender üblicherweise Hypothesen aufstellt und sich sukzessive diejenigen Zusammenhänge ansieht, die ihn interessieren, läuft beim Data Mining der Modellerstellungsprozess vollständig datengetrieben ab. Dies bedeutet, dass das System selbst in der Lage ist, Hypothesen zu generieren und interessante Zusammenhänge ans Tageslicht zu befördern.
Um Erkenntnisse aus Kundendaten abzuleiten und diese für zukünftige Anwendungsfälle zu nutzen, stehen drei wesentliche Data-Mining-Methoden zur Verfügung, die sich folgendermaßen charakterisieren lassen:
- Klassifikation: Aus einer Menge von Elementen mit bekannter Klassenzugehörigkeit wird ein Klassifikator abgeleitet. Der Klassifikator ist ein Modell zur Beschreibung der Klassen auf Basis der Elementeigenschaften. Er ist das Ergebnis eines überwachten Lernprozesses, in dessen Verlauf er zunächst an bekannten Klassenzuordnungen trainiert und anschließend an Testdaten validiert wird.
Beispiel: Modell, mit dem auf der Grundlage demographischer Daten ermittelt werden kann, ob eine bestimmte Person potentieller Käufer oder Nicht-Käufer eines neuen Produkts ist. - Segmentierung: Eine Menge von Elementen wird in Gruppen mit ähnlichen Elementeigenschaften (Cluster) eingeteilt. Jedes Cluster zeichnet sich durch eine charakteristische Verteilung der Eigenschaften aus. Da die Anzahl der Cluster sowie die einzelnen Clusterelemente a priori unbekannt sind, handelt es sich hier um einen nicht-überwachten Lernprozess, der durch die Bestimmung der Ähnlichkeit zwischen den Elementen gesteuert wird. Beispiel: Modell, mit dem die Kunden eines Internetproviders auf der Basis ihres Surfverhaltens in fünf charakteristische Kundengruppen eingeteilt werden können.
- Assoziation: Aus einer Menge von Elementen werden Korrelationen zwischen einzelnen Elementen und deren Eigenschaften abgeleitet. Jede Korrelation wird durch eine Assoziationsregel repräsentiert. Wie bei der Segmentierung handelt es sich um einen nicht-überwachten Lernprozess.
Beispiel: Modell, mit dem sich beschreiben lässt, welche Produkte eines Supermarkts mit großer Wahrscheinlichkeit in Verbindung mit bestimmten anderen Produkten gekauft werden (Warenkorbanalyse).
In der praktischen Umsetzung werden die beschriebenen Data-Mining-Methoden durch entsprechende Data-Mining-Techniken (Algorithmen) abgedeckt. Zu den Hauptvertretern der Klassifikationstechniken gehören Entscheidungsbäume und Entscheidungsregeln sowie fallbasierte Verfahren (Nächste-Nachbar-Klassifikatoren, Case Based Reasoning) und neuronale Netze (Multi Layer Perceptrons*). Zur Segmentierung eignen sich Kohonen-Netze (selbstorganisierende Karten) und Clusteranalysverfahren. Korrelationen und sequentielle Muster lassen sich am besten durch Assoziationsregeln beschreiben.
Herkömmliche Analysetechniken, wie statistische Funktionen, Regressionsverfahren und die Datenvisualisierung, können gut zur Ergänzung der beschriebenen Data-Mining-Methoden herangezogen werden.
Prozess der Wissensextraktion
Um aussagekräftige Modelle für CRM-Anwendungen zu erstellen, sind mehrere Schritte erforderlich. Der hier beschriebene Prozess steht im Einklang mit etablierten Vorgehensmodellen, wie dem CRISP-Modell („Cross industry standard process“ ist eine Methodologie für die Umsetzung von Data-Mining-Projekten), betont aber gewisse Aspekte, die aus unserer Sicht für die praktische Umsetzung wichtig sind.
Die wesentlichen Prozessschritte stellen sich wie folgt dar:
- Definition der Aufgabenstellung: Hauptgegenstand der ersten Phase ist die genaue Festlegung der Zielsetzung, die mit der Datenanalyse erreicht werden soll. Diese Festlegung erfolgt üblicherweise im Rahmen einer Geschäftsfallbeschreibung, in der neben den Analysezielen auch Kenngrößen für die Erfolgsmessung spezifiziert werden sollten. In diesem Zusammenhang ist auch die Beleuchtung des Geschäftswertbeitrags wichtig, d.h. man sollte Klarheit darüber gewinnen, ob die Anwendung auf eine Umsatzsteigerung, eine Kostenreduktion oder einen bestimmten Wettbewerbsvorteil abzielt. Dieser Punkt ist vor allem im Hinblick auf die spätere Auswahl der Daten und Analysemethoden entscheidend.
- Aufbau der Mining-Datenbasis: Nach der Festlegung der Analyseziele kann mit dem Aufbau der Datenbasis begonnen werden. Hierbei handelt es sich um die aufwendigste Phase des Gesamtprozesses, da für die Erzeugung guter Modelle hohe Ansprüche an die Daten gestellt werden. Dies gilt sowohl im Hinblick auf die Datenauswahl als auch die Datengranularität (Feinheits- bzw. Auflösungsgrad der
Daten) und Datenqualität. Gegenstand der Datenauswahl, die in Abstimmung mit den Analysezielen erfolgen muss, ist zunächst die Fokussierung auf die relevanten Datenattribute sowie gegebenenfalls eine bestimmte Teilmenge des gesamten Datenpools. Darüber hinaus können Berechnungen oder Aggregationen erforderlich sein, um interessante Kenngrößen aus den Rohdaten abzuleiten, ebenso wie man mittels Transformationen und Formatumwandlungen eine Bereinigung der Daten herbeiführen sollte. Wichtig ist in diesem Zusammenhang auch die Erkennung und Behandlung fehlender und fehlerhafter Werte, um die erforderliche Datenqualität zu gewährleisten. Mit dem Aufbau der Mining-Datenbasis sind die Vorbereitungen für die Modellbildung abgeschlossen. - Erzeugung von Modellen: Im eigentlichen Data-Mining-Schritt des Wissensextraktionsprozesses werden nun in Abstimmung mit der vorher definierten Aufgabenstellung die geeigneten Methoden und Algorithmen für die Modellerstellung ausgewählt. Die Auswahl hängt vor allem davon ab, ob das Modell eher zur anschaulichen Beschreibung der Daten (Deskription) oder zur Vorhersage (Prädiktion) verwendet werden soll. In jedem Falle ist es sinnvoll, mit unterschiedlichen Algorithmen einen aus mehreren Modellen bestehenden Pool zu generieren, aus dem man bei der anschließenden Ergebnisinterpretation das beste Modell auswählt. Jedes einzelne Modell zeichnet sich durch die spezifische Wahl der Modell- und Trainingsparameter aus.
- Interpretation der Ergebnisse: In diesem Schritt werden die erzeugten Modelle hinsichtlich ihrer Güte untersucht und bewertet. Die Bewertung sollte alle wichtigen Aspekte einschließen und deshalb nicht nur, wie oftmals üblich, die Genauigkeit als Kriterium berücksichtigen. Letztere drückt aus, welchen Prozentsatz einer vorgegebenen Testmenge das Modell korrekt beschreibt bzw. wie stark das Modell von den Testdaten abweicht. Darüber hinaus sollte bei einem Vorhersagemodell bewertet werden, in welchem Maße es die in Phase 1 definierten Kenngrößen für die Erfolgsmessung verbessern kann wie beispielsweise die Responserate oder der Gewinn einer Marketingkampagne. Zielt ein Modell dagegen vorwiegend auf die anschauliche Beschreibung der zugrunde liegenden Daten ab, ist vor allem der Grad an Erkenntnisgewinn zu beurteilen, der durch das Modell erreicht wird. Hierzu müssen die Ergebnisse von einem Fachexperten auf Nützlichkeit, Plausibilität und Konsistenz mit bereits vorhandenem Wissen überprüft werden.
- Repräsentation und Anwendung der Ergebnisse: Das im Rahmen der Ergebnisinterpretation am besten bewertete Modell wird schließlich in eine operative CRM-Anwendung inkorporiert. Für die konkrete Umsetzung sind dabei mehrere Wege denkbar. Zum einen könnte man die gefundenen Erkenntnisse in geeigneter Form aufbereiten, in eine Wissensbasis einstellen und so einem bestimmten Anwenderkreis, wie z.B. einer Vertriebsabteilung, zugänglich machen. Zum anderen liegt es nahe, das extrahierte Modell direkt an den Schnittstellen zum Kunden einzusetzen. Für die Optimierung der zum Kunden gerichteten Interaktionen (z.B. Bestimmung der Zielgruppe für eine Marketingkampagne) würde man das Modell dann am besten auf die Kundendatenbank anwenden, während zur Behandlung der vom Kunden ausgehenden Interaktionen das Modell in die entsprechenden Vertriebs- und Serviceapplikationen integriert werden muss (z.B. ein Tool, das den Call-Center-Agenten bei jedem Anruf Vorschläge für Cross-Selling-Möglichkeiten unterbreitet).
Auch wenn die obige Darstellung eine lineare Abfolge der einzelnen Schritte impliziert, ist es bei der praktischen Umsetzung unvermeidlich, mehrere Feedback-Schleifen zu durchlaufen. So können z.B. Erkenntnisse, die man aus der Interpretation eines Modells gewinnt, Anlass dafür sein, dass man die Erzeugung des Modells mit anderen Modellparametern wiederholt oder sogar eine andere Auswahl von Eingabegrößen für die Modellbildung wählt. Die Wissensextraktion aus Daten ist somit ein iterativer Prozess.
Um die Betrachtung des Modellbildungsprozesses abzurunden, möchten wir noch betonen, dass gerade im CRM-Umfeld die Gültigkeit von Modellen aufgrund veränderter Randbedingungen nur von beschränkter Dauer ist. Deshalb ist es zentraler Bestandteil unserer Data-Mining-Philosophie, die Modellerzeugung in regelmäßigen Abständen automatisiert zu wiederholen und auf diese Weise die Aktualität der Modelle sicherzustellen.
Anwendungsgebiete von Data Mining im Bereich CRM
In den meisten Unternehmen gibt es eine Reihe von Ansatzpunkten, um bestehende CRM-Prozesse zu verbessern. Große Optimierungspotentiale liegen dabei insbesondere in einer besseren Nutzung der wertvollen Daten, die in der Regel in großem Umfang an den Kundenkontaktpunkten der Vertriebs- und Serviceprozesse anfallen. Zur Erschließung dieser Potentiale eignen sich Data-Mining-Verfahren, deren wichtigste Anwendungsfelder wie folgt zusammengefasst werden können:
- Systematische Neukundengewinnung,
- Zielgerichtete Kampagnendurchführung,
- Bonitäts- und Risikoanalyse,
- Kundenwertanalyse,
- Warenkorbanalyse,
- Cross- und Up-Selling,
- Entwicklungsprognose für einzelne Kundensegmente,
- Zusammenstellung kundengerechter Produktangebote,
- Untersuchung der Vertriebsweg-Affinität,
- Kündigungsprävention,
- Personalisierung.
Das große Einsatzpotential von Data-Mining-Verfahren im Bereich CRM soll im folgenden anhand mehrerer praktischer Beispiele illustriert werden. Dabei wird auch deutlich, dass sich sehr viele Projekte nicht nur auf eines der oben genannten Anwendungsgebiete konzentrieren, sondern mehrere Anwendungsfelder und Methoden kombinieren, um zum Erfolg zu kommen.
Zielgerichtete Kampagnendurchführung mittels Data Mining
In vielen Branchen wird ganzheitliches CRM heute durch Direktmarketingaktivitäten in allen Phasen des Kundenlebenszyklus unterstützt.
Folgendes Beispiel zeigt auf welche Weise Data Mining dabei hilft den Wirkungsgrad einer Marketingkampagne zu verbessern und die Kampagnenkosten zu optimieren.
Ein Händler plant den Vertrieb eines neuen Buches über eine Direktmailing-Kampagne. Hierzu kann er auf eine Kundendatenbank mit insgesamt 500.000 Einträgen zurückgreifen, wobei von jedem Kunden neben den demographischen Daten auch die Kundenhistorie sowie die Liste der vorher gekauften Bücher vorliegt. Ziel ist es, zunächst ein Interessenten-Profil zu ermitteln, um mit einer möglichst geringen Anzahl von Anschreiben eine möglichst hohe Zahl von Interessenten zu erreichen. Die Kosten für ein Anschreiben, und damit der Verlust pro Nicht-Besteller, betragen 0,85 Euro, der Gewinn pro verkauftem Buch liegt bei 29,20 Euro.
Zunächst wird eine Testkampagne mit 20.000 zufällig ausgewählten Personen durchgeführt und sorgfältig analysiert. Die Bestellrate liegt bei 1.8 Prozent. Aus den Daten der Interessenten wird auf der Basis von Entscheidungsregeln ein prädiktives Modell abgeleitet, mit dem vorhergesagt werden kann, welche Personen sehr wahrscheinlich auf das Angebot eingehen werden.
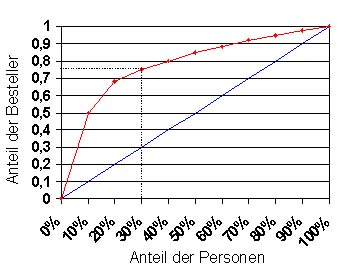
Das extrahierte Modell wird anschließend auf die verbliebenen 480.000 Personen angewendet. Das Ergebnis ist in Form eines Gains Charts (Abbildung 1) dargestellt, aus dem deutlich sichtbar ist, dass bereits 75 Prozent der potentiellen Besteller erreicht werden können, wenn man sich auf die interessante Zielgruppe beschränkt. Diese umfasst ca. 30 Prozent des Personenpools, d.h. ungefähr 150.000 Personen wurden im Rahmen der gezielten Marketingkampagne angeschrieben.
Abbildung 1: Gains Chart mit Vorhersagemodell (rot) und ohne Modell (blau).
Durch die Anwendung des mit Data-Mining-Methoden erstellten Vorhersagemodells war es möglich, die Bestellrate auf 5.0 Prozent zu steigern. Dies ist das 2.8-fache des Referenzwertes der Testkampagne, bei der noch keinerlei Erkenntnisse über die Zusammensetzung der Zielgruppe vorlagen. Wie man sieht, kann durch moderne Analyseverfahren also ein großes Optimierungspotential bei der Kampagnenplanung erschlossen werden.
Noch eindrucksvoller wirkt sich der Einsatz des Vorhersagemodells auf den finanziellen Erfolg der Hauptkampagne aus. Eine entsprechende Betrachtung zeigt nämlich, dass mit der zielgerichteten Kampagne ein Gewinn von 200.000 DM erreicht wurde, während die zufällige Auswahl von 150.000 Personen zu einem Verlust von 82.000 DM geführt hätte. Beim Versenden eines Anschreibens an alle Personen hätte sich gar ein Verlust von 273.000 DM ergeben. Diese Zahlen machen deutlich, dass sich effektive und gewinnbringende Werbekampagnen überhaupt erst nach einer wissensbasierten Ermittlung der Zielgruppe durchführen lassen.
Systematische Neukundengewinnung mittels Data Mining
Der erste Schritt des CRM-Zyklus besteht in der Identifikation von Interessenten und deren Überführung in Kunden. Dabei ist es von großem Vorteil für ein Unternehmen, wenn dieser Prozess möglichst systematisch abläuft und nur diejenigen Interessenten zu Kunden konvertiert werden, die bestimmte Anforderungen erfüllen. Wir wollen betrachten, wie man mit Data-Mining-Methoden eine systematische Neukundengewinnung erreichen kann.
Ein Kreditkartenunternehmen führt jährlich mehrere Direktmailing-Kampagnen durch, bei denen jeweils eine Million Personen angeschrieben werden. Ziel dieser Kampagnen ist es, den angeschriebenen Personenkreis zur Beantragung einer Kreditkarte zu bewegen und dadurch einen Interessentenpool zu generieren. Bevor allerdings ein Antrag akzeptiert wird, führt das Unternehmen eine Risikoanalyse durch. Dieser Schritt ist notwendig, da auf ein Kreditkartenangebot deutlich mehr zahlungsschwache als zahlungskräftige Personen eingehen.
Für die Durchführung der Risikoanalyse wurde ein neuronales Modell erstellt, das auf der Basis von historischem Datenmaterial trainiert wurde. Dazu hat man eine repräsentative Menge von Kunden ausgewählt, von denen neben den existierenden Personendaten auch eine verlässliche Risikoeinschätzung vorlag. Die Daten wurden in eine Trainings- und eine Testmenge aufgeteilt. Nach Auswahl der geeigneten Beschreibungsgrößen und Abschluss der Trainingsphase war das Modell in der Lage, jeder Person anhand ihrer Merkmale eine Risikoeinschätzung zuzuordnen. Die Zuverlässigkeit des Vorhersagemodells konnte auf der Testmenge bestätigt werden.
Alle Personen, die im Zuge einer Neukundengewinnungskampagnen einen Antrag auf eine Kreditkarte gestellt haben, konnten somit einer Risikobewertung unterzogen werden, wobei das vorher erstellte Modell die Funktion eines Scoring-Instruments hatte. Durch den Einsatz dieses Instruments wurden gezielt 20 Prozent der Antragsteller mit den besten Bewertungen ausgewählt und als Kunden akzeptiert.
Erwähnt werden sollte an dieser Stelle noch, dass wie im vorhergehenden Beispiel auch die eigentliche Kampagnendurchführung und Zielgruppenoptimierung durch Data-Mining-Verfahren unterstützt wurde.
Kündigungsprävention mittels Data Mining
Für nahezu jedes Unternehmen übersteigen die Kosten für die Akquisition neuer Kunden diejenigen Kosten, die für die Bewahrung profitabler Kunden aufgewendet werden müssen. Dies gilt insbesondere für den Telekommunikationssektor, in dem die Kundenloyalität relativ gering ist.
Als Beispiel betrachten wir einen Mobilfunkanbieter in den USA mit ca. 500.000 Kunden. Die jährliche Abwanderungsrate liegt wie im Branchendurchschnitt bei 25 Prozent im Jahr, die Akquisitionskosten pro Kunde betragen $300. Daraus resultieren jährlich Kosten von $37.5 Mio. für die Ersetzung der abgewanderten Kunden. Dies ist Anreiz genug, um ein Kundenbindungsprogramm durchzuführen mit dem Ziel, Abwanderungstendenzen frühzeitig zu erkennen und geeignete Gegenmaßnahmen einzuleiten.
Um ein Modell für die Identifikation von Kundengruppen mit hoher Abwanderungsrate zu erstellen, musste zunächst eine geeignete Datengrundlage geschaffen werden, die möglichst alle verfügbaren Informationen über den Kunden berücksichtigt. Die demographischen Kundendaten wurden deshalb durch eine Reihe von Kennzahlen erweitert, die das Telefonierverhalten und die Kundenhistorie widerspiegeln. Auf dieser Basis konnte ein aussagekräftiges Modell für die Vorhersage der Abwanderungsrate erstellt werden.
Da man mit Kundenbindungsprogrammen vor allem die wertvollen Kunden erreichen möchte, wurde in einem zweiten Schritt ein Modell zur Identifikation der profitablen Kunden erstellt. Die Feststellung, ob ein Kunden profitabel ist oder nicht ist dabei keine Fragestellung des Data Mining, sondern das Ergebnis einer Berechnung, die auf einer bestimmten Definition des Kundenwerts beruht. Erst durch den Einsatz von Data-Mining-Verfahren ließ sich aber ein Vorhersagemodell ableiten, mit dem die Höhe des Kundenwertes in Beziehung zu charakteristischen Kundenmerkmalen gesetzt werden konnte.
Die alleinige Identifikation von wertvollen Kunden mit hoher Abwanderungstendenz ist jedoch noch nicht hilfreich, solange keine geeigneten Gegenmaßnahmen eingeleitet werden. Deshalb wurden in einem dritten Schritt Angebote ausgearbeitet, die Kunden von einer Kündigung abhalten sollten (z.B. Sondertarife für Kunden, die überwiegend lange Telefonate mit einem definierten Gesprächspartner führen). Die Zuordnung des attraktivsten Angebots zu einem bestimmten Kunden war dann erneut Gegenstand eines Modellierungsverfahrens.
Zusammenfassend wurden im Rahmen des Projektes zur Kündigungsprävention also insgesamt drei Modelle verwendet. Mit dem ersten Modell wurden alle potentiellen Abwanderungskandidaten identifiziert, das zweite Modell hat aus dieser Menge alle profitablen Kunden herausgefiltert, deren Kündigung verhindert werden sollte, und mittels des dritten Modells wurde diesen Kunden schließlich das attraktivste Angebot zugeordnet. Das Ergebnis war eine Reduktion der Abwanderungsrate auf 20 Prozent, was einer jährlichen Einsparung von $7.5 Mio. bei der Akquisition entspricht. Auch an diesem Beispiel zeigt sich deutlich, dass Data Mining einen großen Beitrag zur Verbesserung der Kundenbeziehungen leisten und in diesem Zusammenhang signifikante Einsparpotentiale erschließen kann.
Fazit
Customer Relationship Management ist eine wesentliche Voraussetzung, um auf den heutigen Märkten wettbewerbsfähig zu sein. Je effektiver man Kundendaten und Kundeninformationen nutzt, desto profitabler kann man sein Geschäft gestalten. In diesem Sinne stellt analytisches CRM durch die Ableitung von Erkenntnissen und Vorhersagemodellen aus Kundendaten nicht nur eine entscheidende Unterstützung für das operative CRM dar, sondern ermöglicht in vielen Fällen überhaupt erst den Aufbau profitabler Kundenbeziehungen. Oder anders ausgedrückt: erfolgreiches Kundenmanagement erfordert das umfassende Verständnis der Kunden und ihrer Bedürfnisse und Data Mining leistet eine wichtigen Beitrag zur Erreichung dieses Ziels.
*Neuronale Netze sind Modellierungsverfahren aus dem Bereich der
Künstlichen Intelligenz. Insbesondere die Netzarchitektur des Multi Layer
Perceptrons eignet sich sehr gut für die Modellierung komplexer (d.h.
hochdimensionaler und nichtlinearer) Zusammenhänge in Daten.
Autor: Dr. Joachim Keppler, Viveon AG
eingestellt am 7. Oktober 2002